Slavonic - мост между прошлым и настоящим
Требуются программисты, владеющие
церковно-славянским языком.
Если вы подумали, что эпиграф это шутка, спешим вас уверить, что нет. Кирилл и Мефодий, решая для современных им славян проблему письменности на берестяных грамотах, понятия не имели, какую проблему они создают для письменности компьютерной. Вероятно, они не без основания полагали, что ко времени появления первых PC придуманная ими письменность в достаточной мере эволюционирует и абстрагируется от греческого наследия, оставив в своем алфавите только необходимый минимум для комфортного клавишного ввода. И в целом, надо сказать, их предположение оправдалось, хотя на заре русской компьютерной эры и возникли некоторые сложности с вводом кириллической кодировки. Но могли ли они представить, что до наших времен сохранятся люди, которые не только будут уметь читать древние письмена, но и возжаждут печатать их десятипальцевым слепым методом. Тут-то внезапно и выяснится, что церковно-славянский язык, великолепно вписываясь в пространство иконы, с неуклюжим скрипом едва втискивается в пространство современной клавиатуры.
Дело тут вот в чем.
Во-первых, букв в церковно-славянском языке ощутимо больше, чем в русском и тем более в латинском алфавитах. Большинство славянских букв имеют русские эквиваленты, и для них ввод с клавиатуры, на первый взгляд, проблемы не представляет. Нажал на русскую клавишу ‘а’ – в редактор вводится славянская буква ‘а’. Все такие буквы удобно и интуитивно понятно печатаются в русской раскладке клавиатуры. Но некоторые славянские буквы имеют более одного начертания, а иные вовсе не имеют русских аналогов (зато, уж понятно, что имеют аналоги греческие). Как быть с ними? Здесь удобства заканчиваются и вместе с интуицией плавно переносятся на улицу. Для ввода таких букв изворотливому писателю приходится подключать небуквенные клавиши или латинскую раскладку. Если вам однажды доводилось вводить с клавиатуры список идентификаторов, в которых перемешаны русские и латинские буквы, вы должны были уже насторожиться. Постоянное переключение раскладки доставляет немалые неудобства. Но уверяем вас, это ничто по сравнению с вводом славянских букв. Например, желая ввести английскую букву R, вы находите знакомое начертание на клавиатуре и жмете в аккурат туда, а когда вам в английской раскладке требуется ввести загадочную славянскую букву, на подсказку рассчитывать не приходится.
Во-вторых (и в самых страшных), в церковно-славянском языке используются многочисленные надстрочные знаки: три вида ударения, придыхание, три сочетания придыхания с ударениями, ерок, кендема, краткая, простое титло и разнообразные буквенные титла. Как вы думаете, насколько при таком пышном великолепии увеличивается общее количество вариантов для вводимых с клавиатуры символов? На языке программистов это называется комбинаторным взрывом. Ничего подобного в русском языке давно нет. Все лишние буквы упразднили большевики. Ну, осталось у нас, конечно, одно единственное ударение, но вам хоть раз требовалось вводить его с клавиатуры? Буквотитла же просто прекрасны. Это когда по щучьему велению следующая буква слова пишется не после предыдущей, а над ней, при этом произвольное количество прочих букв можно вовсе не написать для общности. Когда на иконе в углу закончилось место, бесспорно удобно иметь возможность писать текст сразу во все стороны – хочешь вправо пиши, хочешь вверх. Но при вводе с клавиатуры мы как-то больше привыкли писать исключительно слева направо, и перспектива печати текста в иных направлениях изрядно озадачивает.
Все вышеописанное едва не поставило жирный крест на дружбе церковно-славянского языка и компьютерной грамотности. Главная проблема – запредельное количество различных начертаний символов, под которое просто не хватит никаких кнопок на клавиатуре.
Национальная идея наладить производство церковно-славянских клавиатур с полем клавиш 1000 x 1000 ни в чью светлую голову не пришла. Дело ведь тут не только в железе, но и в софте. Каждой клавише (символу) соответствует строго определенный числовой код, который и отправляется в глубины подсознания компьютера, когда на эту клавишу нажимают. Соответствие между символами и их кодами называется кодировкой. Кодировка штука конвенциальная – как договоримся, так и закодируем. Для каждого человеческого языка с его уникальными алфавитными символами есть своя собственная кодировка. У русского языка их даже несколько (не спрашивайте зачем, никто не знает). Так уж вышло, что в любой стандартной кодировке всего-то лишь 256 кодов символов – ровно столько, сколько чисел можно закодировать в одном байте или в восьми битах. Такая кодировка поэтому еще называется 8-битной. Алфавитам большинства нормальных языков с головой хватало 256 символов как для родных букв, так и для буржуйских. И еще место оставалось – под символы пунктуации, процента, доллара (куда же без него), параграфа и проч. И все равно оставалось место – под всякие черточки косые и прямые, которыми в старом DOS-е рисовали таблицы. Но об этом уже не будем.
Поэтому смысла делать более широкие кодировки (больше 256 элементов) не было никакого. И даже еще меньше его было, если вспомнить, что каждый символ кодировочной таблицы требуется уметь вводить с обычной клавиатуры. Уверяем вас, что если вы посчитаете клавиши на своей родной клавиатуре, их окажется сильно меньше 256. И можно поспорить, что клавиатура с 256 клавишами вам не понравится совсем. В общем, очевидное правило такое - чем меньше необходимых символов, тем быстрее и удобней ввод, и тем меньше места на столе занимает клавиатура. Из-за такой экономии некоторые символы 8-битной кодировки невозможно ввести нажатием одной клавиши – требуется вводить целую последовательность или даже вовсе полный числовой код символа. Например, попробуйте, удерживая клавишу ALT, ввести цифры 0174 и будет вам символ ®.
Возвращаемся к церковно-славянскому языку. Для ветвящегося множества его чудесных символов 256 допустимых вариантов это, в общем, ни о чем. При желании он израсходует всю 8-битную кодировочную таблицу и попросит еще 3 раза по столько же. Но если вы внимательно читали выше, больше 256 в 8-битной кодировке ему никто не даст.
«А как же юникод? Есть же юникод!» – возразят нам знакомые с проблемой 8-битных кодировок читатели. В юникоде каждому символу под код отводится целых два байта (а можно и больше). В два байта влезают 65535 различных кодов, а значит, туда можно напихать церковно-славянские символы во всей красе. Спору нет, можно. И более того, уже напихали. Только нашу проблему это не решило. Сейчас объясним почему. Еще раз пересчитайте клавиши на своей клавиатуре, повторяя в уме слово «юникод». Стало ли их больше? Не стало. А это и есть ответ. Как вы будете вводить 65535 священных церковно-славянских символов на клавиатуре с 60-ю кнопками? Поэтому юникод - не выход. И нужен он под нечто другое. Представьте, что потратив весь Великий Пост, вы сумели напечатать письмо своему японскому другу зачем-то на церковно-славянском языке. Если вы сохраните письмо в кодировке юникод, она гарантирует вам, что ваш японский друг увидит ваше письмо ровно в тех символах, которыми вы его написали. Это, конечно, не гарантирует, что он поймет написанное, но, по крайней мере, правильно оценит. Однако если он захочет подкорректировать ваше письмо, у него возникнут ровно те же трудности, что были при наборе у вас – куда бы тут чего нажать, чтобы вылезла нужная «Омега красивая с придыханием».
На самом деле Юникод это просто сборище различных кодировок, где каждой выделен свой личный диапазон в общем пространстве 65535 кодов. Вот взяли какой-нибудь шаманский язык со всеми тридцатью тремя его невиданными буквами, выделили ему диапазон в свободной зоне (не занятой буквами других чудесных языков) и сказали, что отныне и навеки в этом диапазоне будут кодироваться исключительно они – эти невиданные ранее буквы. Если текст на шаманском сохранить в юникоде, все числовые коды букв будут из этого диапазона. И кто бы такой файл ни открыл, при наличии шрифта с поддержкой нужного диапазона, он узрит истинно шаманскую письменность и ничто другое. Но где-то в далекой шаманской стране все равно есть старомодная 8-битная кодировка шаманского, которая позволяет шаманам быстро и удобно вводить с обычной клавиатуры все 33 буквы.
Все вышенаписанное было написано за тем, чтобы вы поняли – без упаковки церковно-славянского языка в 8-битную кодировку не обойтись. Поначалу, как у нас издревле на Руси водится, таких кодировок было сделано сразу много. Каждый русский программист или создатель красивого церковно-славянского шрифта, погружаясь в тематику, неизменно считал своей миссией создание новой кодировки для церковно-славянских букв. В общем, типичная домонгольская Русь – в каждом княжестве свои порядки. Кончилось тоже плохо. Церковно-славянский текст, кудряво набранный одним шрифтом, при переключении на другой шрифт становился нечитаемой абракадаброй из славянских букв. Приходилось создавать и использовать специальные программы – конвертеры, которые перегоняли текст из одной мало кому известной кодировки в кодировку малоизвестную, но другую.
Но потом, наконец, один умелый программист победил остальных и создал наиболее удачную 8-битную кодировку, которую на данный момент можно считать стандартом. Называется она ucs8, а прочитать про нее можно здесь https://www.irmologion.ru. Удачность ее в том, что в ней грамотно продумано расположение символов, а главное – их состав. Мы уже упоминали о том, что запихнуть в 8-битную кодировку все множество славянских символов принципиально нельзя. Значит, речь, в любом случае, идет о некоем компромиссе – какие-то варианты символов придется отбросить, либо заменить их на комбинацию из двух символов. Например, гласную под острым ударением можно ввести при помощи двух символов – собственно гласной и идущего за ней символа ударения. В церковно-славянском шрифте начертание символа ударения выполняется таким образом, что он как бы смещается к предыдущей букве. И создается визуальное ощущение, что это один символ – гласная с ударением:
а1
Возникает искушение подумать, что это отличный прием, который позволит все варианты надстрочников свести к двухсимвольному. Но тут не так все просто. Буквы разные, а символ надстрочника один и тот же. Над одними он будет нависать вполне эстетично, а на другие может коряво наезжать. Причем ситуация даже для одной и той же буквы может меняться для различных шрифтов. Т.е. в одном шрифте ударение над данной гласной смотрится гармонично, а в другом шрифте оставляет желать лучшего. И просто поменяв шрифт в редакторе, вы получите проблемы с начертанием.
Поэтому для таких потенциально проблемных букв хорошо бы в кодировку ввести собственный символ, где буква будет нарисована вместе с ударением. Такой символ называется лигатурой. А у нас появится два способа ввести символ с ударением – либо символ + ударение, либо лигатура. В таком случае лигатура должна быть предпочтительней для ввода, поскольку она гарантирует корректное написание символа с ударением в любом шрифте, в отличие от двухсимвольного варианта.
В идеале для каждой комбинации буквы и надстрочника можно было бы ввести собственную лигатуру, гарантировав корректное начертание. Но как мы уже сказали, 256 кодов для этого не хватит, и с клавиатуры их вводить было бы нереально сложно. Поэтому в 8-битной кодировке допустимое количество лигатур сильно ограничено, а правильный выбор их множества и делает кодировку ucs8 удачной.
Но даже в кодировке ucs8 ввод церковно-славянских текстов представляет собой нелегкую задачу. Во-первых, нужно постоянно переключаться с русской раскладки на английскую. Во-вторых, нужно помнить соответствие между латинскими и славянскими буквами. В-третьих, нужно помнить, где на клавиатуре расположены многочисленные надстрочники, их варианты для заглавных букв, а также все их комбинации. В-четвертых, нужно помнить, какие лигатуры присутствуют в кодировке, чтобы при вводе отдавать предпочтение им, а не двухсимвольным комбинациям. Почти все пространство кодировки ucs8 в игре, а это значит, что у вас для ввода как бы алфавит из примерно 230 букв. Набор церковно-славянского текста в таких условиях потребует извлечения поистине нетривиальных септаккордов на клавиатуре, и если джазовый гитарист это не вы, вас ждут серьезные испытания.
Одна из альтернатив клавишному вводу – виртуальная клавиатура. Это когда клавиатура рисуется на экране компьютера, а пользователь нажимает нужные символы мышкой. На виртуальной клавиатуре можно нарисовать сколько угодно лигатур и любые комбинации надстрочников. Но не спешите кричать «Ура!», вспомните про юникод. Во-первых, мышкин ввод быстро утомляет. Если с виртуальной клавиатуры вам требуется ввести пароль для входа в мобильный банк, это ничего – терпимо. Но набор даже одной страницы обычного (не церковного и не славянского) текста быстро убедит вас в необходимости искать более удобные варианты для печати. Во-вторых, если изображать на виртуальной клавиатуре все возможные варианты символов, не хватит места даже на ней. Если отобразить только саму кодировку ucs8 – будет недостаточно, придется снова подбирать нужные символы для двухсимвольных комбинаций. В-третьих, искать нужный символ на виртуальной клавиатуре тоже задача не простая.
Таким образом, перед церковно-славянским писателем вырисовываются две обидные альтернативы – либо работать мышкой в виртуальной клавиатуре, либо учить аккорды клавиатурных раскладок. Все программы до Славоника предлагали пользователям именно эти два пути.
Славоник открывает иной путь.
Идея выросла из осознания простого факта - ни один народ не разговаривает на церковно-славянском языке уже несколько веков. Вообще-то, сам церковно-славянский язык никогда и не был разговорным – он изначально был создан как язык возвышенных богослужений. Но древние болгары и славяне разговаривали на очень похожем древнеславянском. И словарный запас у этих языков очень сильно пересекался. Благодаря эволюции разговорного древнеславянского в церковно-славянском могли запросто появляться новые слова. С появлением великого и могучего потомка эволюция церковно-славянского языка остановилась. Сейчас на нем звучат лишь написанные давным-давно одни и те же тексты. А если и пишутся тексты новые, то будьте уверены, они целиком состоят из того же древнего набора слов. Отсюда и молитва об освящении вашей колесницы производства BMW, например. Любая попытка обогатить церковно-славянский язык современными словами неизбежно закончится «издревле лётчиком», как было с одним сказочным персонажем.
Вот эта конечность множества церковно-славянских слов и открывает новые перспективы для компьютерной верстки соответствующих текстов. Для начала представьте, что человечеству удалось создать словарь всех словоформ церковно-славянского языка в кодировке ucs8. Откуда взять такой словарь, мы поговорим чуть ниже, а сейчас допустим, что он у нас просто есть. В нем все возможные слова написаны правильно – со всеми полагающимися ударениями и другими надстрочниками.
Идея №1. Что если при вводе церковно-славянского слова не заставлять писателя вбивать все хитросплетенные буквы и надстрочники, а попытаться угадать, какое слово он собирается вводить и предложить ему готовых кандидатов из словаря на выбор? Такая штука называется автозаменой. С ней хорошо знакомы программисты. Например, когда программист пытается набрать название функции GetQueuedCompletionStatusEx, вежливый редактор предложит ему готовое написание этой функции задолго до того, как программист доберется до «GetQue». Ведь редактор знает названия всех функций. Поначалу, например, при вводе первых двух букв “Ge” кандидатов может быть очень много, т.к. множество функций начинаются на Get. Но чем больше букв будет введено, тем меньше будет список кандидатов. На «GetQue…» список сократится до двух-трех названий, из которых без труда можно выбрать нужное и не вводить руками оставшийся хвост “…uedCompletionStatusEx”. Теперь представьте, что этот хвост – церковно-славянские буквы с надстрочниками, которые вам вручную вводить больше не придется никогда.
Идея №2. Предыдущая идея великолепна, если вы еще не осознали это сами. Но все же начала слов придется вводить руками. А если там в начале слова должны быть надстрочники, которые вы забыли? А если вы перепутаете букву и, например, вместо широкой n введете обычную о? Или вместо э напишите е? В таком случае начало введенного вами слова не будет совпадать со словарным, и редактор не сможет предложить вам правильных кандидатов на замену. Но только не Славоник – этот сможет. Это и есть идея №2. Славонику вообще все равно, сколько ошибок вы сделаете при вводе. Мы зашили в нем хитрющий алгоритм, который редуцирует любое церковно-славянское слово к некоторой специальной форме - ключу. Уникальность алгоритма в том, что слова, написанные с различными ошибками, редуцируются в итоге в такому же ключу, что и слова, написанные безупречно правильно. Как бы вы ни наошибались при вводе слова, Славоник с большой вероятностью сумеет распознать, что вы имели в виду на самом деле и предложит вам правильный вариант, с которым вам останется только согласиться.
Идея №3. Все это прекрасно. Но все это прекрасно лишь при условии, что у нас есть вышеупомянутый словарь. Кого бы попросить сделать такой словарь хотя бы тысяч на тридцать словоформ? И сколько, интересно, на это уйдет человеко-лет? Ответ неожиданный. Если подумать в другую сторону, то станет очевидно, что всю необходимую работу за нас уже сделали. К настоящему моменту в сети полно церковно-славянских текстов, набранных в кодировке ucs8. И большинство из них выверены. Осталось написать программу индексатор, которая разберет эти тексты на отдельные слова и составит из них наш словарь. Одна Библия тут чего стоит. А есть еще молитвословы и патристика. В общем, только на некоторых библейских книгах мы без труда собрали словарь на те самые 30’000 словоформ.
Идея №4. Итак, словарь словоформ у нас есть. Все предыдущие идеи заработали со страшной силой. Но все же в некоторых случаях Славоник пока не может подсказать правильных кандидатов. Например, слово «ангел» по церковно-славянски пишется как «а4гг7лъ», и ключи у этих слов все-таки будут разными. Рассчитывать на то, что оператор вспомнит, как правильно пишется это слово, вряд ли стоит. Но тут полезно будет вспомнить про гражданский шрифт. Это когда церковно-славянский текст набирается не церковно-славянским шрифтом, а обычным, гражданским. Большинство современных молитвословов на церковно-славянском языке набраны именно гражданским шрифтом. По сути это современная транскрипция. При чтении слова, записанные гражданским шрифтом, звучат абсолютно так же, как их церковно-славянские написания. Большинство церковно-славянских текстов имеют аналоги, набранные гражданским шрифтом. При этом последовательность слов в обоих текстах строго одинакова. Для нас это означает, что можно точно так же построить не просто словарь ц-сл словоформ, а словарь с транскрипцией, где каждому ц-сл слову будет соответствовать его написание гражданским шрифтом. И вот в таком словаре можно будет найти не только «а4гг7лъ», но и «ангел», и значит, предложить правильного кандидата даже в этом случае.
На самом деле, мы пошли еще дальше. Словарь Славоника состоит из трех частей – церковно-славянское слово, транскрипция и русский перевод. Поэтому при вводе в редактор можно начинать вбивать русское слово. Например, вбиваете вы «глаз», а Славоник предлагает вам «џко». Или вам нужно написать «болото», но как оно звучит по славянски, вы просто не знаете. Славоник предложит вам правильный вариант «бaра», едва вы успеете ввести «боло..».
К сожалению, словарь с русским переводом создать автоматически сложнее. Русские тексты далеко не всегда пословно соответствуют славянским. Но строгость законов на Руси, как известно, компенсируется необязательностью их исполнения. Поэтому русский перевод вбивать в словарь не обязательно. Впрочем, и транскрипцию тоже необязательно. Но желательно.
Идея №5. Уже почти лучше некуда. Но на самом деле есть. Все-таки до полноты словаря нам пока далеко, хоть мы и верим, что этот день придет. Но пока при вводе могут потребоваться словоформы, которых в словаре еще нет. Да и сам словарь нужно ведь как-то наполнять. Для таких слов мы придумали еще один список кандидатов – только в этот раз это не слова, а отдельные символы. Если список кандидатов-слов редактор выводит снизу от вводимого слова, то список кандидатов-букв – сверху. Например, вводите вы голую «и», а Славоник предлагает вам сверху полный список всех вариантов начертания для этой буквы «<и3 и4 и5 ї ј v3 v4». Стрелками влево-вправо в этом списке можно быстро выбрать нужный вариант - ваша голая «и» заменится на выбранный вариант с надсточником. А можно просто нажать клавишу 'и' несколько раз - будут перебираться ее варианты. При этом Славоник знает, какие варианты допустимы, а какие нет. Например, если введенная гласная первая в слове, то будут предложены варианты с придыханием, а если не первая – придыхания в списке не будет.
Такой способ ввода мы назвали контекстной клавиатурой. Ее преимущества перед обычной виртуальной клавиатурой очевидны. Во-первых, вы видите только те символы, которые вас интересуют в текущий момент, а не все символы вообще. В примере выше это только варианты буквы «и», причем идущей в начале слова. Во-вторых, при работе с контекстной клавиатурой не нужна мышка – нужный вариант можно прекрасно выбрать при помощи клавиш-стрелок.
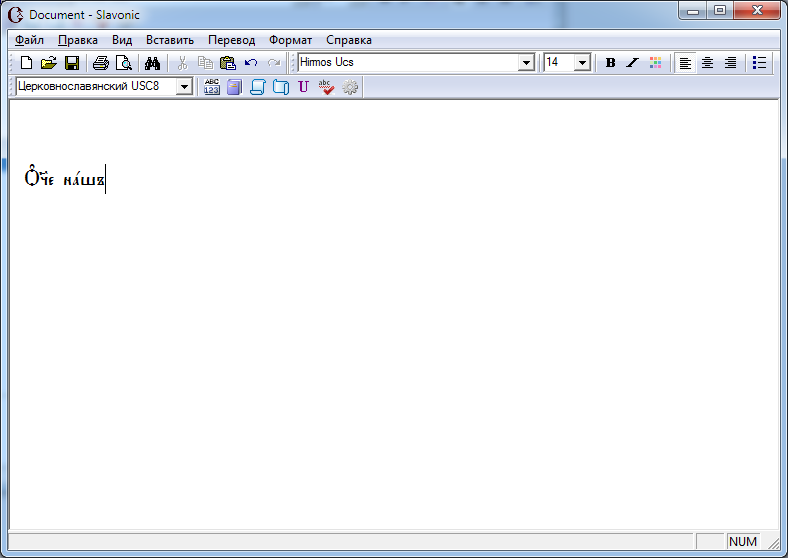
Настало время привести пример. Пусть нам требуется вбить в компьютер фразу
Џ§е нaшъ
Если делать это без Славоника - в обычном редакторе, то последовательность действий будет такой.
1. Переключаем редактор на церковно-славянский шрифт и начинаем вводить.
2. Вводим большую букву О. Стоп. Простая буква «О» нам не подойдет, поскольку в начале слова должна идти «О» широкая. Заглавная «О» широкая это английская буква «O». Переключаемся в английскую раскладку и вводим английскую «O».
3. Теперь ищем подходящий надстрочник. Нам нужно придыхание и острое ударение одновременно – это называется исо. Причем для большой буквы. Для строчных букв используются другие варианты надстрочников. Исо для большой буквы это клавиша $. Нажимаем. Получается плохо – исо налезло на букву. Как раз тот самый случай.
4. Стираем все, что навводили. Ищем в кодировочной таблице лигатуру Џ. Находим – это символ с кодом 0x8F. А какой клавише на клавиатуре он соответствует? Извините, никакой. Либо открываем таблицу символов (виртуальную клавиатуру), находим символ с кодом 143 (это 0x8F в десятеричном представлении) и выбираем мышкой, либо вводим с клавиатуры чудовищную последовательность ALT+0143.
5. Теперь надо ввести следующую букву – «ч». Ой, а у нас раскладка английская, мы же в п.2 на нее переключились. Переключаемся обратно на русскую. Вводим русскую «ч». Неужели в этот раз так просто?
6. Теперь нужно ввести простое титло. Это клавиша 7. Тоже вроде просто. Но снова получилось как-то некузяво. Опять есть лигатура? Точно есть – это символ параграфа. Стираем титло и «ч».
7. Эээ… а какой клавише соответствует символ параграфа? Извините, снова никакой. Но это символ с кодом A7, его можно ввести как ALT+0167. Вводим.
8. Дальше… Нет стоп. Хватит. Где там ваш Славоник.
Как это выглядит в Славонике:
Выбросьте всю эту дурь из головы и просто начинайте набирать обычными русскими словами «Отче наш».
После ввода «Отче», и даже раньше, Славоник предложит вам настоящего Џ§е - соглашайтесь. Т.е. стрелкой вниз выберите желаемый вариант и нажмите ENTER
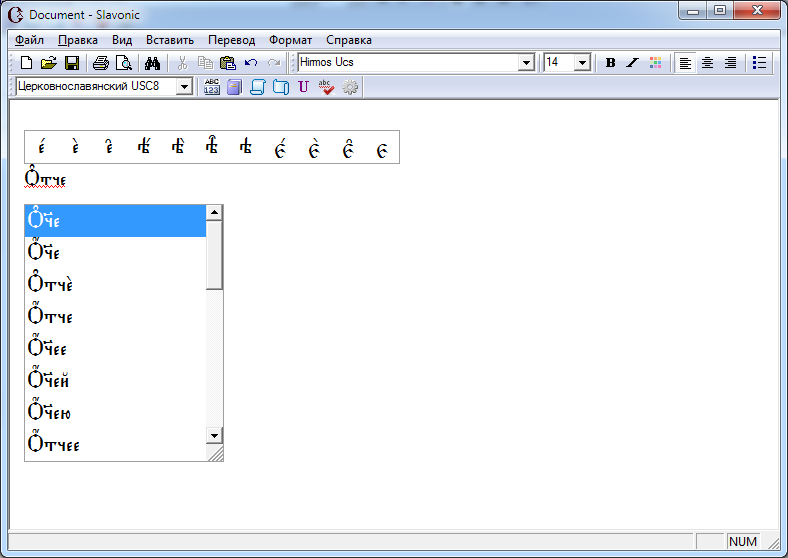
А после ввода «наш» стрелкой вниз выбираем правильное нaшъ:
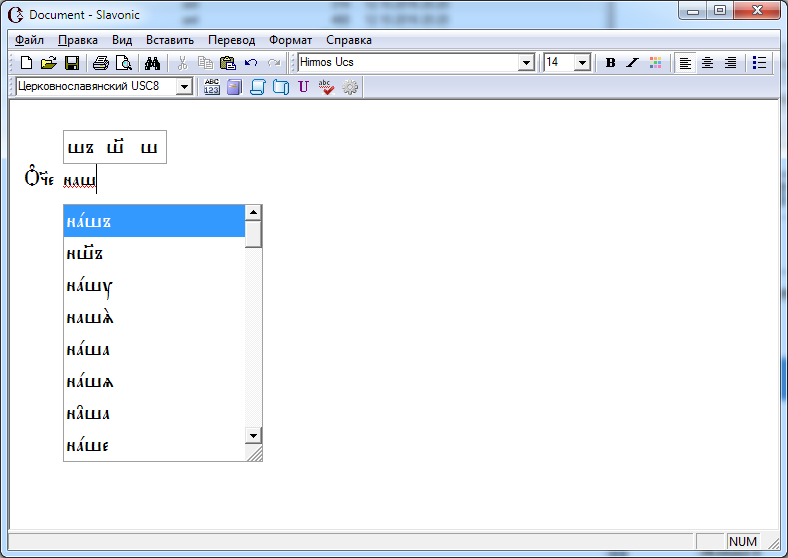
Получилось то, что надо, без никаких усилий: